Optimizing AI Agents: How Replaying LLM Sessions Enhances Performance
Are you looking to optimize your AI agents and enhance their performance? Understanding how changes impact your AI agents in real-world interactions is crucial. By replaying LLM sessions with Helicone, you can directly apply modifications to actual AI agent sessions, providing valuable insights that traditional isolated testing may miss.
Why Replay LLM Sessions for AI Agents?
- Deep Insights into Agent Behavior: See how your AI agents perform in authentic scenarios using production data.
- Uncover Hidden Issues: Identify and address problems that only arise during full session interactions.
- Accelerate Development: Streamline your AI agent development process by testing changes efficiently.
In this guide, we’ll show you how to optimize your AI agents by replaying LLM sessions with Helicone, providing step-by-step instructions and best practices.
What is an AI Agent?
An AI agent is an autonomous software entity that performs tasks on behalf of users with some degree of independence or autonomy, utilizing AI techniques. Optimizing these agents ensures they provide accurate, efficient, and reliable outcomes.
Why Optimize AI Agents by Replaying LLM Sessions?
Replaying LLM sessions allows you to:
- Test Modifications Safely: Experiment with changes without affecting live users.
- Understand Contextual Performance: See how adjustments impact the agent’s behavior over entire sessions.
- Improve User Experience: Deliver more accurate and helpful interactions to users.
Step-by-Step Guide to Enhancing AI Agent Performance
Example Application: AI Debate
We’ll walk through an example of a debate session between a user and an assistant. Between each argument, a impartial assistant scores the argument from 1 to 10.
Step 1: Setting Up Your AI Agent with Helicone
Instrument your AI agent’s LLM calls to include Helicone session metadata for tracking and logging.
Instrumenting Your LLM Calls
-
Configure the OpenAI API client with Helicone
Set up the session headers, configure the OpenAI API client with Helicone, and include the necessary headers when making a request.
const { OpenAI } = require("openai"); const { randomUUID } = require("crypto"); // Generate unique session identifiers const sessionId = randomUUID(); const sessionName = "AI Debate"; const sessionPath = "/debate/climate-change"; // Initialize OpenAI client with Helicone baseURL and auth header const openai = new OpenAI({ apiKey: process.env.OPENAI_API_KEY, baseURL: "https://oai.helicone.ai/v1", defaultHeaders: { "Helicone-Auth": `Bearer ${process.env.HELICONE_API_KEY}`, }, }); // Include Helicone session headers when making requests const response = await openai.chat.completions( { model: "gpt-4o-mini", messages: conversation, }, { headers: { "Helicone-Session-Id": sessionId, "Helicone-Session-Name": sessionName, "Helicone-Session-Path": sessionPath, }, } ); -
Initialize the conversation with the assistant
const topic = "The impact of climate change on global economies"; const conversation = [ { role: "system", content: "You're a debating professional. You're engaging in a structured debate with the user. Each of you will present arguments for or against the topic. Keep responses concise and to the point.", }, { role: "assistant", content: `Welcome to our debate! Today's topic is: "${topic}". I will argue in favor, and you will argue against. Please present your opening argument.`, }, ]; -
Loop through the debate turns
let turn = 1; while (turn <= MAX_TURNS) { // Get user's argument const userArgument = await promptUser("Your argument: "); conversation.push({ role: "user", content: userArgument }); // Score the user's argument await evaluateArgument( userArgument, "Your Argument", sessionId, sessionName, sessionPath ); // Assistant responds with a counter-argument const assistantResponse = await generateAssistantResponse( conversation, sessionId, sessionName, sessionPath ); conversation.push(assistantResponse); // Score the assistant's argument await evaluateArgument( assistantResponse.content, "Assistant's Argument", sessionId, sessionName, sessionPath ); turn++; }Note: The functions
promptUser,evaluateArgument, andgenerateAssistantResponsehandle user input, argument evaluation, and generating assistant responses, respectively.
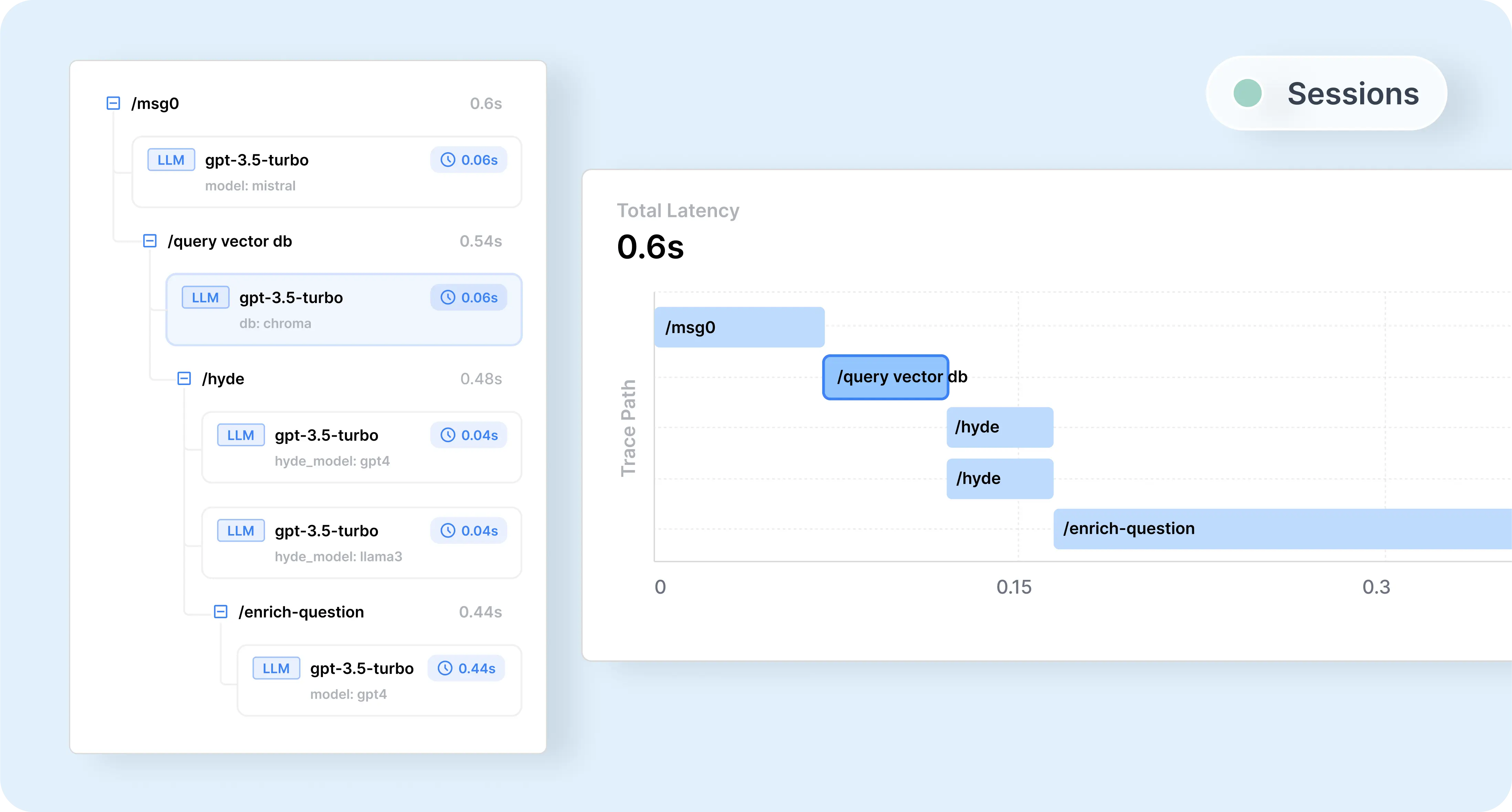
After setting up and running your session through Helicone, you can view it in Helicone:
Go fullscreen for the best experience.
Read more about how to implement Helicone sessions here.
Step 2: Retrieving Session Data
Use Helicone’s API to fetch session data for analysis.
const response = await fetch("https://api.helicone.ai/v1/request/query", {
method: "POST",
headers: {
"Content-Type": "application/json",
Authorization: `Bearer ${HELICONE_API_KEY}`,
},
body: JSON.stringify({
filter: {
properties: {
"Helicone-Session-Id": {
equals: SESSION_ID_TO_REPLAY,
},
},
},
}),
});
const data = await response.json();
Read more about Helicone’s API here.
Step 3: Replaying and Modifying Sessions
Modify session data to test improvements.
-
Parse and sort the requests
Sorting session data can be complex because each use case is unique and may require custom logic. For our debate session example, we simply sort the requests by their
created_attimestamp.const requests = data.data.map((request) => ({ created_at: request.request_created_at, session: request.request_properties["Helicone-Session-Id"], signed_body_url: request.signed_body_url, request_path: request.request_path, path: request.request_properties["Helicone-Session-Path"], prompt_id: request.request_properties["Helicone-Prompt-Id"], body: request.body, })); requests.sort((a, b) => new Date(a.created_at) - new Date(b.created_at)); -
Modify the request bodies as needed
For example, we can adjust the system prompts to change the assistants argument or argument evaluation response.
function modifyRequestBody(request) { if (request.prompt_id === "argument-evaluation") { const systemMessage = request.body.messages.find( (msg) => msg.role === "system" ); if (systemMessage) { systemMessage.content += " Keep the feedback short and concise."; } } else if (request.prompt_id === "assistant-argument") { const systemMessage = request.body.messages.find( (msg) => msg.role === "system" ); if (systemMessage) { systemMessage.content += " Take the persona of a genius in this field when responding."; } } return request; } -
Replay the modified session
// Create a new session for the replay const replaySessionId = randomUUID(); for (const request of requests) { const modifiedRequest = modifyRequestBody(request); // Reuse session metadata from the original request await handleChatCompletion(modifiedRequest); } async function handleChatCompletion(modifiedRequest) { const { body, path, prompt_id, request_path } = modifiedRequest; // Send the modified request to the LLM const response = await fetch(request_path, { method: "POST", headers: { Authorization: `Bearer ${OPENAI_API_KEY}`, "Helicone-Auth": `Bearer ${HELICONE_API_KEY}`, // Reuse the session metadata for logging "Helicone-Session-Id": replaySessionId, "Helicone-Session-Name": sessionName, "Helicone-Session-Path": path, "Helicone-Prompt-Id": prompt_id, }, body: JSON.stringify(body), }); }Note: In the
handleChatCompletionfunction, we send the modified request to the LLM. By reusing the samesession-name,session-path,prompt-id, andrequest pathfrom the original requests, we ensure that the replayed session is logged in Helicone under the same session metadata. This allows you to see the replayed requests in Helicone, grouped under the same session, making it easier to compare and analyze the effects of your modifications.
After running the replay, you can view it in Helicone:
Go fullscreen for the best experience.
With the replayed session now visible in Helicone, you can observe how the modifications impact the AI’s responses throughout the session. This visualization shows how changes in prompts or configurations affect subsequent interactions.
Optional: Evaluations & Prompt Versioning
Evaluations
To assess the impact of your changes quantitatively, use Helicone’s evaluation features to assign scores to both the original and replayed sessions. Comparing these scores helps you understand the effects of your modifications and refine your prompts more effectively.
Prompt Versioning
Helicone’s prompt versioning feature allows you to manage and compare different versions of your prompts effectively. By maintaining multiple versions, you can test various combinations within your sessions to identify which prompts yield the best results. To retrieve specific prompt versions, use Helicone’s Prompt API.
Here’s how you can iterate over prompt versions to test different compositions in your sessions:
Define a list of prompt versions for each prompt.
For each combination in the cartesian product of prompt versions:
Generate a new session ID.
For each prompt in the combination:
Fetch the prompt content using Helicone's Prompt API.
Run the session using the retrieved prompts.
Alternatively, as described above, you can manually modify the prompts after retrieving the session, and Helicone will automatically log the new prompt versions for you. In this approach, you create the prompt versions first.
Conclusion
By focusing on replaying LLM sessions, you can significantly enhance the performance of your AI agents. Helicone provides the tools necessary to make this process efficient and effective, leading to better user experiences and more robust AI applications.
Helicone Plug 🧊
Helicone is the ultimate open-source LLM observability platform built for developers to monitor, debug and improve their LLM applications. We’re fully open source and built to handle high usage use-cases seamlessly. With over 1.8 billion requests and 1.6 trillion tokens logged, it’s proven at scale. Check out our open-source GitHub repository here.
Trusted by Industry Leaders: Companies like Sunrun, Michelin, QAWolf, Slate Magazine, and many more rely on Helicone to enhance their AI models and workflows.
You can view the full code used in this guide on GitHub.